We zijn bezig met de bouw van een Ghost Analyst bovenop Claude van Anthropic, om incidenten in Microsoft Sentinel en Defender te triëren. De flow is rechttoe rechtaan:
- Een alert vuurt af.
- De agent haalt de relevante Entra ID-logs op.
- De agent schrijft de KQL-queries die hij nodig heeft.
- Aan de andere kant ontvangt een analist een opgeschoonde triage-rapportage.
Het probleem is dat triage-data klant-IP’s bevat, gebruikersnamen, interne hostnames en bedrijfsdomeinen. Dat allemaal naar een cloudmodel sturen zonder filter ertussen is niets wat wij willen doen. Een lokaal model zou de privacykant oplossen, maar geen enkel open-source model dat we testten kwam in de buurt van Claude Opus op dit type redeneren. We hadden een tussenweg nodig: een frontier-model blijven gebruiken, en klantdata daar buiten houden.
Dus bouwden we een Data Loss Prevention-laag.
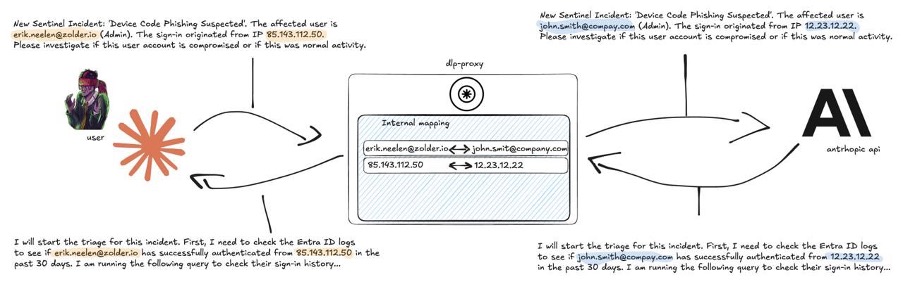
Onze aanpak
De proxy zit tussen de agent en de Anthropic API in:
- Hij pseudonimiseert gevoelige data op de uitgaande weg.
- Hij herstelt de originelen op de terugweg.
- Het LLM ziet nooit echte data. De analist ziet nooit nepdata.
Dat is de makkelijke versie van het verhaal. In de praktijk brak het volledig wegmoffelen van data het redeneervermogen van het LLM, en het kostte drie iteraties om de proxy van een domme regex-gum naar een context-bewuste vertaler te krijgen. Deze post is de lange versie van hoe we daar gekomen zijn, en waarom we het resultaat open source maken.
V1: regex en de “Sarah Kowalski”-hallucinatie
De eerste versie was naïef. Regex matchte e-mailadressen en verving ze door tags tussen blokhaken, dus [email protected] werd [User_Email_1]. Twee problemen kwamen direct naar boven.
Syntactische hallucinaties. Gedwongen om met blokhaak-tags te werken, sloeg Claude terug. LLM’s zijn next-token voorspellers die getraind zijn op echte code en echte data, dus een query als where UserPrincipalName == "[User_Email_1]" is een statistische anomalie. Om de syntax te “repareren” verzon Claude een geloofwaardig ogende gebruiker met de naam sarah.kowalski en begon queries voor haar te schrijven. Wij vroegen om een triage-rapport en kregen fanfictie.
Entiteit-fragmentatie. De volgende poging gebruikte plausibele nepnamen zoals [email protected]. Claude pikte de e-mailstructuur direct op en begon queries te schrijven tegen alleen john.smith. Onze proxy zocht naar de volledige e-mailstring om terug te vertalen, miste de gedeeltelijke match, en de queries leverden niets op.
Prompt engineering had het model kunnen dwingen om mee te werken, maar het architectonische doel was een transparante proxy. Als elk tool dat de proxy aanroept eigen prompt-regels nodig heeft, dan heeft de proxy gefaald.
V2: NER, gestructureerde pseudoniemen en het contextvacuüm
Twee veranderingen: betere detectie, en vervangingen die er echt uitzien.
Detectie. Een licht Named Entity Recognition-model (spaCy) dat naast de regex-pass meedraait. NER pikt persoons- en organisatienamen in natuurlijke taal op die regex niet kan bereiken.
Vervanging. Syntactisch geldige pseudoniemen in plaats van blokhaak-tags. [User_1] werd [email protected]. Claude accepteert dat als een echt e-mailadres, stopt met hallucineren, en schrijft correcte KQL. Om het fragmentatieprobleem uit V1 op te vangen registreert de proxy nu zowel het volledige e-mailadres als de kale gebruikersnaam wanneer hij iets als [email protected] ziet, zodat een latere verwijzing naar alleen rik ook netjes terugvertaald wordt.
De V2-detectiepijplijn liep in drie passes:
- Regex voor e-mailadressen, IP’s, domeinen en bekende-entiteit-patronen uit config.
- spaCy NER voor persoons- en organisatienamen.
- Username-extractie uit het lokale deel van gedetecteerde e-mailadressen.
V2 onthulde meteen het volgende probleem. Pseudonimisering haalde precies die kenmerken weg die het LLM nodig heeft om over een security-incident te redeneren.
- Onmogelijk reizen. Wanneer een gebruiker eerst inlogt vanuit Nederland en daarna vanuit Rusland, signaleert Claude dat normaal gesproken. Na maskering worden beide IP’s willekeurige plaatshouders zoals
198.51.100.1en198.51.100.2. Het model heeft geen enkele manier om te weten dat ze op verschillende continenten zitten. - Typosquatting. Een echt aanvallersdomein als
miicrosoft.comis een rode vlag voor een model dat een miljard domeinnamen gezien heeft. Gemaskeerd alsdomain-external-005.netis dat signaal weg. - Intern versus extern. Met elk domein herschreven naar
domain-external-NNN.netkan Claude bedrijfsinfrastructuur niet onderscheiden van aanvallersinfrastructuur.
V3: context-behoudende pseudonimisering
Een token proxy voor de SOC kan geen domme gum zijn. Hij moet een vertaler zijn: PII eruit halen, de metadata laten staan die het LLM nodig heeft om te redeneren.
ASN-bewuste IP-vervanging. De proxy zoekt voor elk IP de ASN en het netwerk op via de MaxMind GeoLite2-database, en vervangt het dan door een ander IP uit dezelfde ASN en hetzelfde subnet. Een Hetzner-IP in Duitsland wordt een ander Hetzner-IP in Duitsland. Een Cloudflare-IP blijft Cloudflare.
Echte input: "[email protected] logged in from 95.216.246.66"
LLM ziet: "[email protected] logged in from 95.216.201.14"
(ander Hetzner-IP, zelfde /16-prefix)
Analist krijgt: "[email protected] logged in from 95.216.246.66"Het model kan nog steeds whois draaien, onmogelijk reizen detecteren en verdachte hosting markeren, allemaal zonder ooit het echte adres te zien.
Classificatie als intern, partner of extern. Entiteiten worden gecategoriseerd in config: internal-pseudoniemen voor bedrijfsdomeinen, partner voor bekende partners, external voor de rest. Het model begrijpt nu dat [email protected] die praat met domain-external-003.net een insider is die met een outsider praat. Precies het soort context waar triage van afhangt.
Optionele domeinpseudonimisering. Soms moet een analist weten of een afzender uit outlook.com of protonmail.com kwam. Domeinpseudonimisering kan onafhankelijk uitgezet worden terwijl e-mailadressen, IP’s en namen wel gemaskeerd blijven.
De strijd tegen false positives
De detectiepijplijn bouwen was nog maar de helft van het werk. De andere helft was de proxy leren wat hij niet moet redacten, want het Microsoft-ecosysteem zit vol strings die op gevoelige data lijken maar dat niet zijn.
Graph API-permissiescopes zoals Policy.ReadWrite.All zien eruit als domeinnamen. Onze V1-proxy pseudonimiseerde vrolijk alles met punten en TLD’s, dus Mail.ReadWrite werd domain-external-042.net en het LLM had geen idee meer welke API hij aanriep. Hetzelfde verhaal voor Azure-propertypaden zoals ConsentContext.IsAdminConsent, KQL-tabelnamen zoals SecurityEvent en SigninLogs, en .NET-exceptionklassen.
In onze eerste gemeten sessie was 82% van de pseudoniem-mappings een false positive: 65 van de 79 waren Graph-permissies of dotted property paths.
De fix was gelaagd:
- Een dotted-property detector die PascalCase-plus-werkwoord-patronen herkent (dekt alle 700+ Graph-scopes).
- Een configureerbare tech-skiplist met 8.000+ KQL-tabel- en kolomnamen.
- Een domain-allowlist voor dingen als mitre.org en virustotal.com.
- CamelCase-detectie die code-identifiers zoals
TimeGeneratedenUserPrincipalNameoverslaat.
Het false-positive percentage zakte van 82% naar bijna nul.
Streaming: het tail-buffer probleem
Server-sent event streaming verraste ons. Wanneer Claude token-voor-token streamt, kan een pseudoniem over twee chunks heen breken: domain-inter komt binnen in de ene, nal-001.com in de volgende. Een naïeve find-and-replace mist die splitsing volledig.
De fix is een tail buffer die de laatste 80 karakters van elke chunk vasthoudt, ze samenvoegt met de volgende, vervanging draait, en alleen het veilige deel doorgeeft. De latency-kost is klein genoeg dat we hem niet betrouwbaar kunnen meten, en pseudoniemen glippen er nooit ongehersteld doorheen.
Een woord over restrisico
De token proxy is een vangnet, geen garantie. Hij vangt de veelvoorkomende patronen (API-keys, credentials, persoonsgegevens), maar geen enkel filter is perfect. Nieuwe formaten, geobfusqueerde data en context-afhankelijke geheimen kunnen er allemaal doorheen glippen. Als een lokaal model het werk aankan, blijft een lokaal model de veiligere keuze. Een frontier-model hosten binnen AWS Bedrock of Microsoft Foundry is een andere optie, waar de proxy waarde toevoegt als defence in depth in plaats van als enige verdedigingslinie.
Probeer het zelf
Pseudonimisering voor cloud-LLM’s is bruikbaar ver buiten de SOC-use case. Overal waar je frontier-model-redenering wilt over data die je niet naar een cloudprovider mag sturen, geldt hetzelfde patroon.
Clone en draai de proxy:
git clone https://github.com/zolderio/token-proxy.git
cd token-proxy
cp config.json.example config.json
# Pas config.json aan met je interne domeinen, bekende entiteiten, etc.
docker build -t llm-token-proxy .
docker run -p 8090:8080 -v ./config.json:/app/config.json llm-token-proxyWijs Claude Code naar de proxy:
export ANTHROPIC_BASE_URL=http://localhost:8090/session/my-session/De proxy wordt geleverd met een lege config. Geen aannames over jouw omgeving. Specifiek voor security operations bevat config.json.example 8.000+ KQL-termen en volledige Graph API-dekking out of the box.
We leveren op dit moment een Anthropic Messages API-adapter, maar de proxy gebruikt een provider adapter pattern: ondersteuning toevoegen voor OpenAI, Google Gemini of een andere provider is één protocolklasse. De kern-pseudonimisering-engine is providerneutraal.
GitHub: github.com/zolderio/token-proxy
Open een issue of stuur een PR als je een use case vindt waar wij niet aan gedacht hebben.


